
Symbolic Music Genre Transfer with CycleGAN(3)
Index
- Intro
- Related Work
- Model Architecture
- Dataset and Preprocessing
- Architecture Parmeters and Training
- Experimental Results
- Conclusion
이 논문에서 사용하는 모델은 Generative adversarial network(GAN)에 기반을 두고 있습니다. Ian Goodfellow et al1에서 제안 된 기존의 모델에서는 Generator G와 Discriminator D가 존재 합니다. G는 노이즈를 실제 데이터 처럼 만드는 역할을 합니다. D는 G가 만들어낸 가짜 데이터와 실제 데이터를 구별하는 역할을 합니다.
Music domain transfer이기 때문에 input데이터는 노이즈가 아니라 실제 음악 데이터이고, 본 논문에서는 음악 데이터중에서 MIDI 데이터를 사용합니다. 해당 논문에서는 두 장르 사이의 변환만 다루기 때문에 target데이터는 다른 장르의 음악입니다. 그렇기 때문에 transfer는 대칭적이어야 합니다. 그래서 CycleGAN을 네트워크 구성에 사용하게 됩니다.
CycleGAN은 기본적으로 순환 방식으로 배열되고 조화롭게 훈련된 2개의 GAN으로 구성됩니다. G의 하나는 A to B, 다른 G는 B to A로 동작하고 D는 G의 output에 붙게 됩니다.
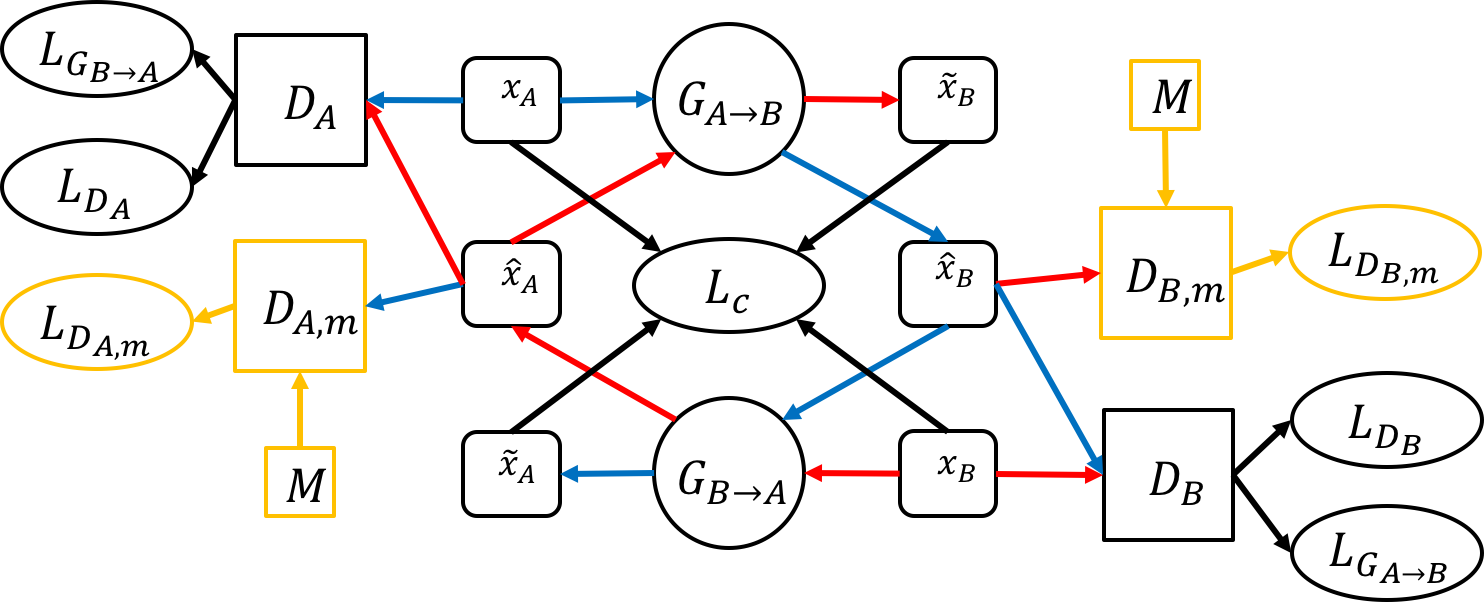
\(G_{A->B}\): A 장르를 B 장르로 바꾸는 G
\(G_{B->A}\): B 장르를 A 장르로 바꾸는 G
\(D_A\) \(D_B\): 첨자 장르를 위한 D
\(G_{A,m}\), \(G_{B,m}\): extra Discriminator이며, G가 high level feature를 학습 할 수 있게 해줌
M: 여러 도메인을 가지고 있는 data sets
\(X_A\)는 원본 도메인이다.
\(hat{X}_A\) = \(G_{A->B}(X_A\))
\(tilde{X}_A\) = \(G_{B->A}\)(\(G_{A->B}(X_A\)))
\({X}_B\)는 \({X}_A\)와 정확히 반대로 동작합니다
G의 Loss로는 L2 norm사용합니다.
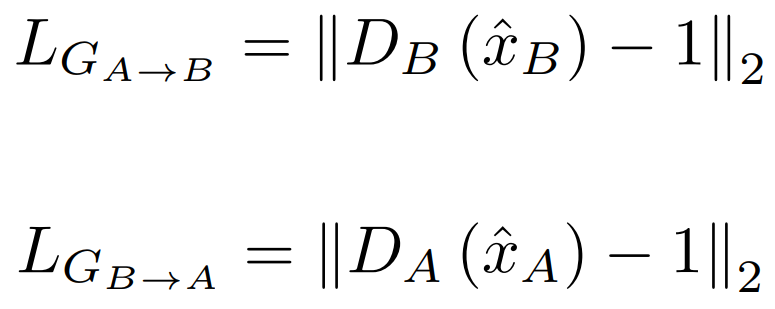
추가적으로 Cycle Consistency loss라는 L1 Loss를 사용합니다. Cycle Consistency loss는 글 아래에 자세한 설명이 있습니다.
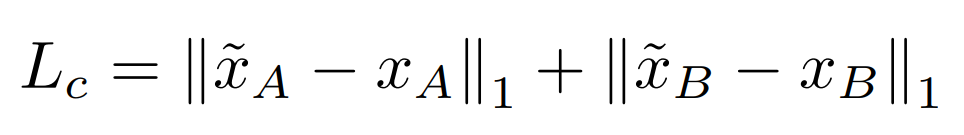
그래서 두 식을 합친 최종적인 Loss는 다음과 같이 표현 됩니다.
\(lambda\)는 Cycle Consistency loss의 가중치입니다.
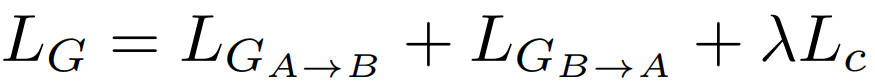
GAN 학습은 안정적이지 못하기 때문에 밸런스 조절이 필요합니다. D가 너무 강력해서 초반부터 G를 압도하게 되면 local optima의 위험을 가지고 있습니다. G가 D를 속이기 위해서는 두 장르의 특징에 대해 효과적으로 학습을 진행해야 합니다. 하지만 음악 장르는 독특한 패턴을 가질 확률이 높기 때문에 D를 속이기 위한 패턴을 만들 확률이 높습니다. D를 속인다고 해서 반드시 들을만한 음악이 나오는 것이 나오진 않습니다. 들을 만한 음악을 만들기 위해선 high level feature가 필요합니다. 그래서 두 개의 extra D (D_x)를 도입합니다. 기존의 D는 fake/real 구분을 하고 \(D_x\)는 G가 music manifold에 잔류하게 도와줍니다. 이를 통해 그럴듯하고 실제적인 음악을 만들어 줍니다. G가 대부분의 입력 구조를 유지하게 하여 원복 조각을 장르 변화 이후에도 유지 할 수 있게 합니다.
다음은 D의 Loss와 \(D_x\)의 Loss입니다.
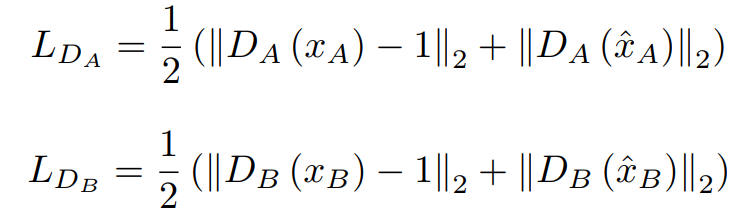
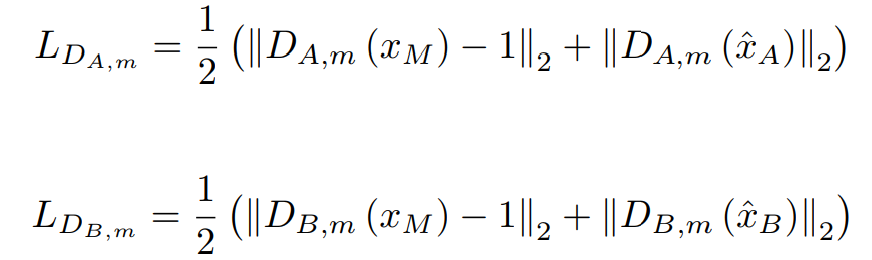
최종적인 Loss의 형태입니다. \(gamma\)는 \(D_x\)의 가중치입니다.
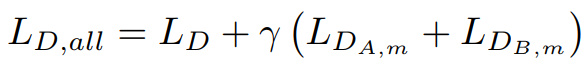
학습의 안정성을 위해 D에 가우시안 노이즈를 추가하게됩니다.
Cycle Consistency Loss
학습의 안정성을 위해 Cycle Consistency Loss를 사용합니다. Cycle Consistency Loss는 mapping을 보장하는 역할을 수행합니다. Cycle Consistency Loss가 없을 경우 posterior collapse또는 mode collapse라는 현상을 경험할 수 있습니다. 이 현상은 이 글을 참조해 주세요. G가 입력 데이터를 무시하지 않고 필요한 정보를 남기고 invert할 수 있게 하는 regularizer의 역할 수행합니다.
1. Generative Adversarial Nets