간단하게 알아보는 Difference between VAE and GAN
What is difference between VAE and GAN
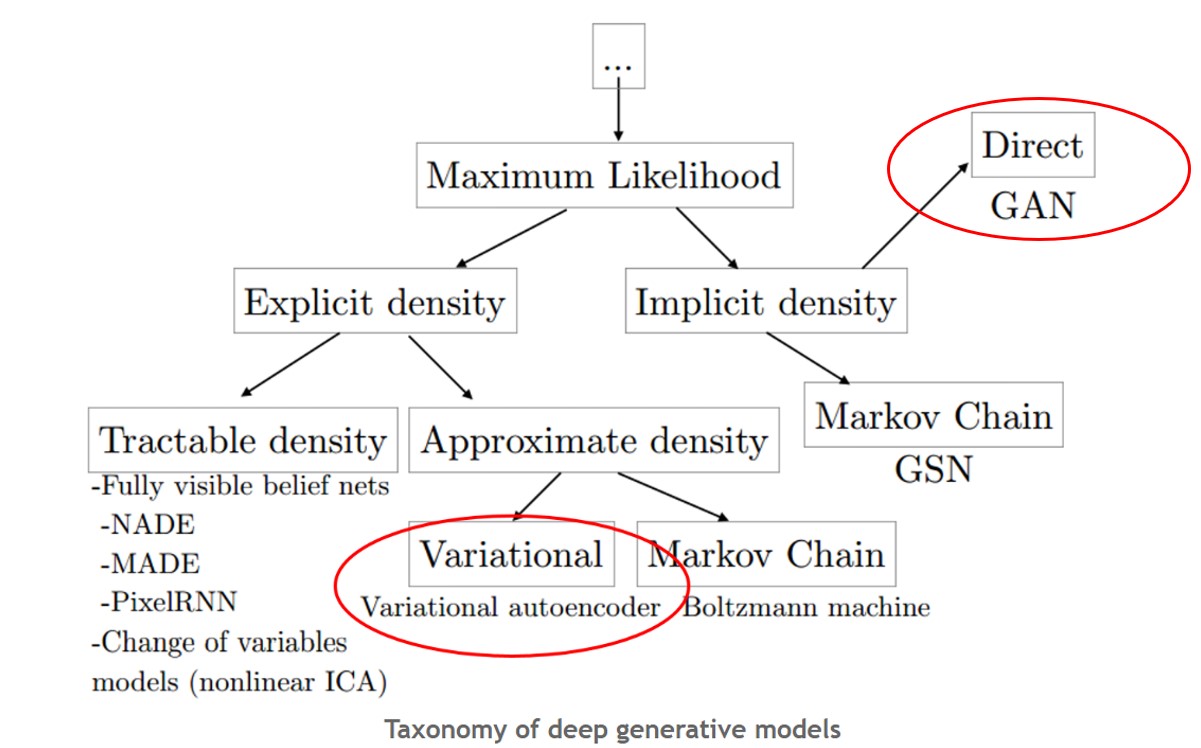
VAE와 GAN은 그림에서 보다시피 Maximum Likehood의 범주에 속하는 방법론이다. 그림에서 볼 수 있든 Explicit한 방법론과 Implicit한 방법론으로 나뉜다. 이 블로그에서 주로 다루는 GAN은 보다시피 Implicit(암시적인)한 방법론을 취하고 있다.
VAE
Variational Autoencoder(AVE)는 Kingma et al1의 논문에서 제안된 네트워크의 구조이다. 복잡한 데이터 생성 모델을 설계하고 대규모 데이터 세트에 적용을 할 수 있게 해준다. input을 z로 encoding하고 스스로 input을 decoding하는 방법을 학습하는 방법이다. 즉 decoding된 output이 input과 최대한 가깝게 만들어는 내는 방법이다.
Loss Function은 input x와 복원된 output x'간의 Loss로 정의한다. VAE는 모델을 명확히 정의하고 이를 최대화 하는 전략을 택한다. 그래서 예측이 가능하지만 동시에 우리가 아는 것 이상의 성능을 내기가 힘들다는 한계가 존재한다. Auto-Encoder가 input 복원하는 것에만 맞게 학습을 하기 때문이다. Encoding되는 잠재변수 z는 의미론적이지 않다.
GAN
Generative adversarial network(GAN)은 Ian J. Goodfellow et al2의 논문에서 제안된 개념이다. 이름 자체를 뜯어보면 Adversarial은 대립하는 뜻을 가지고 있어서 적대적 생성 신경이라는 뜻의 네트워크 모델이다. 이런 뜻을 가지게 된 이유는 Discriminator D와 Generator G가 서로 대립하여 학습하면서 성능을 개선해 나가는 구조를 가지고 있기 때문이다. 논문에서 나온 예시로는 위조 지폐를 만드는 G가 존재하고, 위조지폐를 감별 Classify하는 D가 있다. D와 G는 서로 속이고, 구별하면서 서로 능력이 발전하게 되고, 구별할 확률이 0.5로 수렴하게 된다. 즉 진짜 지폐와 위조 지폐를 구별할 수 없게 된다.
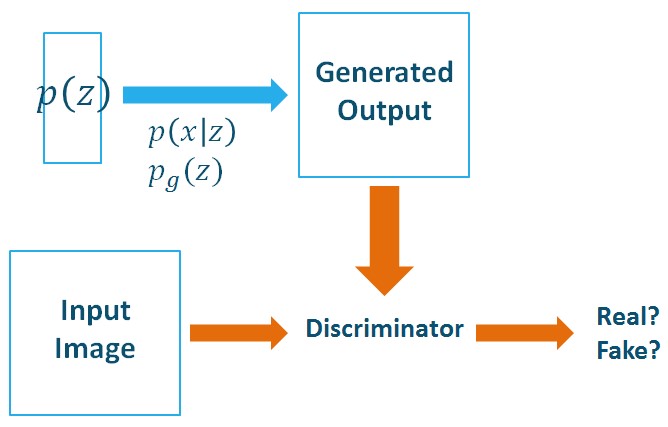
노이즈 p(z)가 들어오면 G는 실제 데이터의 분포와 비슷하게 노이즈를 변형한다. D는 G가 생성한 이미지와 실제 이미지를 받아서 구분하는 과정을 거친다.
차이점
VAE
- Data의 분포를 학습하고 싶은데, 이 data가 intractable하기 때문에 variational inference라는 방법으로 풀어보고자 함
- VAE는 data 분포가 잘 학습되기만 하면 sampling(data generation)이 저절로 따라옴
GAN
- Model의 목적 자체가 어떤 data의 분포를 학습하는 것이 아님
- 진짜 같은 sample을 generate하는 것이 목적으로 고안된 sampler
1. Auto-Encoding Variational Bayes
2. Generative Adversarial Networks
본 포스팅은 졸업작품을 위한 미팅 자료에 기반을 두고 있습니다. 팀원과 함께 진행하는 프로젝트입니다.