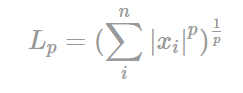Sihan's Blog
Home
Categories
Tags
Archives
Home
Categories
Tags
Archives
// toggle_theme()
#graduation
4 posts
mldl
·
2019년 7월 16일
간단하게 정리한 Mode Collapse
mldl
·
2019년 7월 16일
간단하게 정리한 Norm
mldl
·
2019년 7월 3일
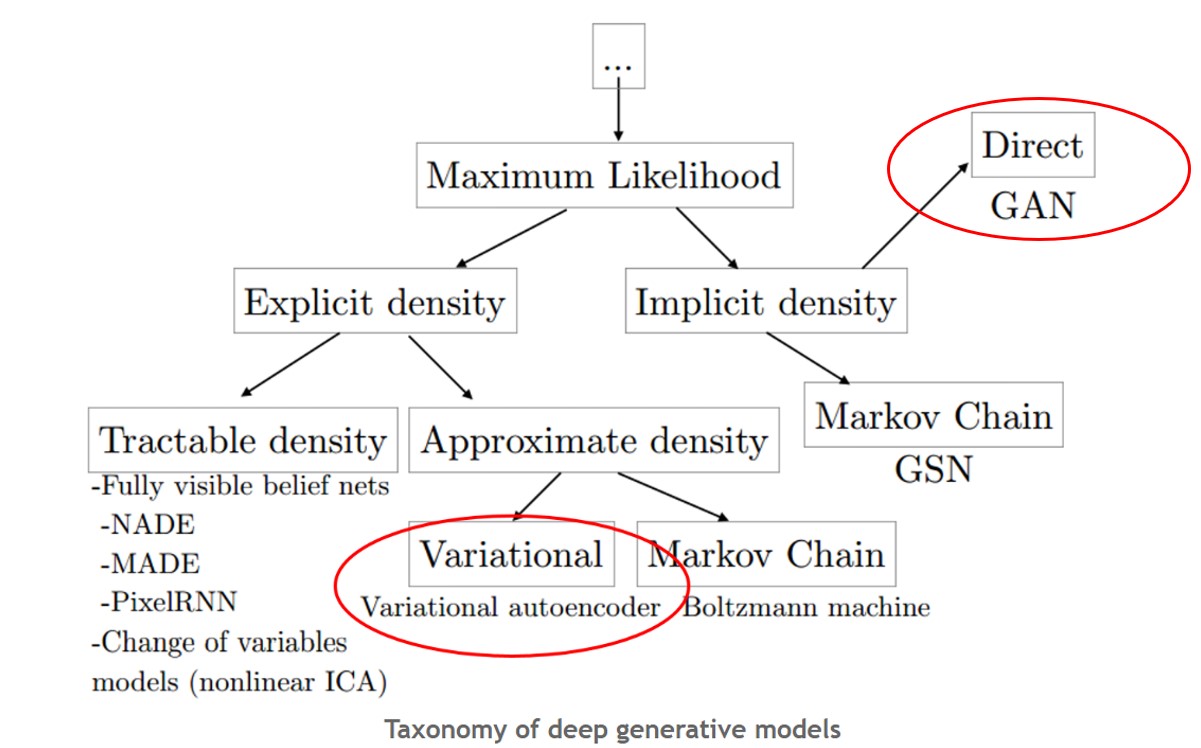
간단하게 알아보는 Difference between VAE and GAN
mldl
·
2019년 7월 1일
Simple Latent Space