간단하게 훑어보는 Advanced CNNs
언제나 처럼 다시 돌아온 간단하게 Deep Learning 개념 정리 글입니다. 자세한 내용은 각 논문을 참조하거나 다른 학술 블로그를 읽어 주세요. 이 글에서 언급 되는 아키텍쳐들에 관한 논문 제목은 글 하단의 각주로 확인해 주세요.
Index
1. AlexNet
2. VGGNet, GoogLeNet
3. ResNet
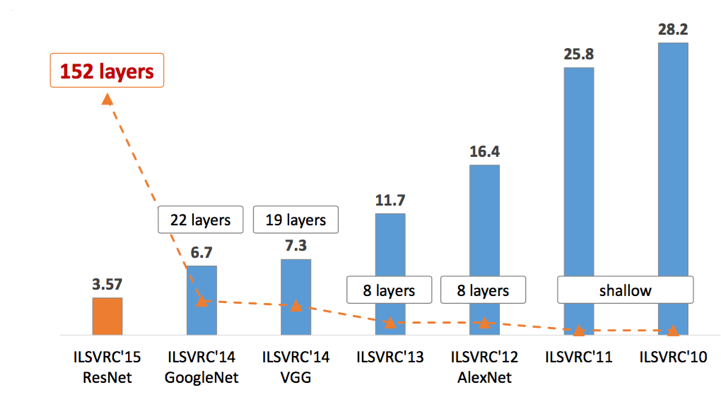
fig.1 ILSVRC 우승 네트워크 레이어 수
2012년 AlexNet을 시작으로 Convolution Neural Network CNN은 빠른 속도로 성능이 좋아지고 위 이미지에서 보이는 것 처럼 레이어가 깊어지기 시작했습니다. 이후 모델들은 가중치 업데이트를 위해 사용한 Error Backpropagation 알고리즘의 단점인 Gradient Vanishing과 Gradient Exploding 문제를 극복하고 나온 모델들입니다.
1st Gen AlexNet
AlexNet은 2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)우승을 차지 하면서 CNN의 부흥기를 가지고 옵니다. 기본적인 아키텍쳐는 CNN의 조상격이라고 할 수 있는 LeNet에서 따왔습니다. AlexNet의 구조적 특징은 GPU를 병렬로 사용하기 위한 병렬 구조입니다. 현재는 많은 프레임워크들이 병렬 연산을 효과적으로 지원하고 있기 때문에 아래와 같은 아키텍쳐를 구성하지는 않습니다.
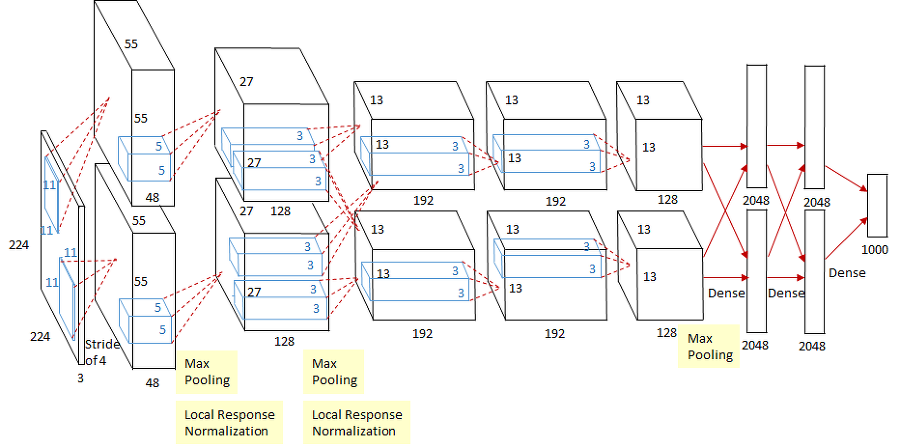
fig.2 AlexNet 구조
AlexNet은 8개의 레이어로 구성되어 있습니다. conv레이어 5개와 Full-connected 레이어 3개가 아키텍쳐를 구성하고 있습니다. GPU를 이용한 병렬 연산을 위해 3번째 conv레이어는 두 채널의 feature map에 모두 연결 되어 있고, 이 외의 레이어들은 같은 채널들만 연결되어 있습니다. 두 채널이 주로 학습 하는 내용에 차이가 있습니다. 첫 번째 채널에서는 주로 컬러와 상관 없는 정보 추출을 위한 kernel이 학습되고, 두 번째 채널에서는 컬러 정보를 추출하기 위한 kernel이 학습됩니다.
이 외의 AlexNet의 특징들은 다음과 같습니다.
LeNet에서 사용했던tanh대신ReLU사용하면서 6배 빠른 속도를 얻었고, 이 후에ReLU의 대중화에 큰 공헌을 하였습니다.overfitting을 막기 위해dropout을 적용했는데,힌튼이 제안한 방법과는 좀 다른 방식으로 사용되어 혼란을 야기하기도 해서dropout은 다른 네트워크를 참조하는 것이 좋을 것 같습니디.- 역시
overfitting을 막기 위해 많은 데이터를 위해data augmentaion을 사용했습니다. 회전, 위치 이동 등으로 같은 이미지에 여러 변화를 줍니다. 또 입력 크기인244 x 244보다 큰 이미지를 생성해 크롭하여서 같은 내용을 담고 있지만 위치가 다른 이미지를 만들기도 합니다. local response normalization (LRN)이란 기법이 적용 되었습니다. 신경 생물학의lateral inhibition 측면 억제개념에서 착안 한 것으로 활성화된 뉴런이 주변 뉴런을 억누르는 현상을 의미합니다. 즉 강하게 활성화 된 주변 뉴런들을normalization합니다.
2nd Gen VGGNet
VGGNet은 2014년도 ILSVRC 준우승 모델이지만 우승모델인 GoogLeNet보다 더 각광을 받았던 모델입니다. 모델의 이름은 Oxford의 visual geometry group이 만든 모델이기 때문에 그 약자를 따서 VGG가 되었다고 합니다.
가장 큰 특징은 모든 conv레이어가 3 x 3크기를 가지고 있다는 것입니다. VGG팀은 깊이의 영향을 확인하고 싶어서 가장 작은 conv레이어 크기인 3 x 3을 이용했다고 합니다. 연산을 거듭할수 이미지의 크기가 작아 지는 conv연산에서 3 x 3레이어를 택했기 때문에 큰 필터를 사용하는 연산에 비해 깊이 쌓을 수 있었던 것으로 보입니다.
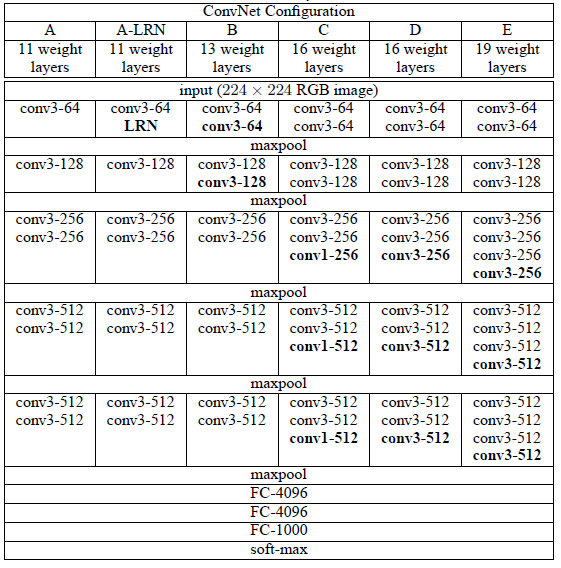
fig.3 VGGNet 구조 표
VGG팀은 총 6개의 모델을 만들어서 성능을 비교했습니다. fig.3의 표에서 D모델이 우리가 VGG16이라고 부르는 모델이고 E모델은 VGG19입니다. 여기서 VGG뒤에 붙는 숫자는 weight layer의 갯수입니다.
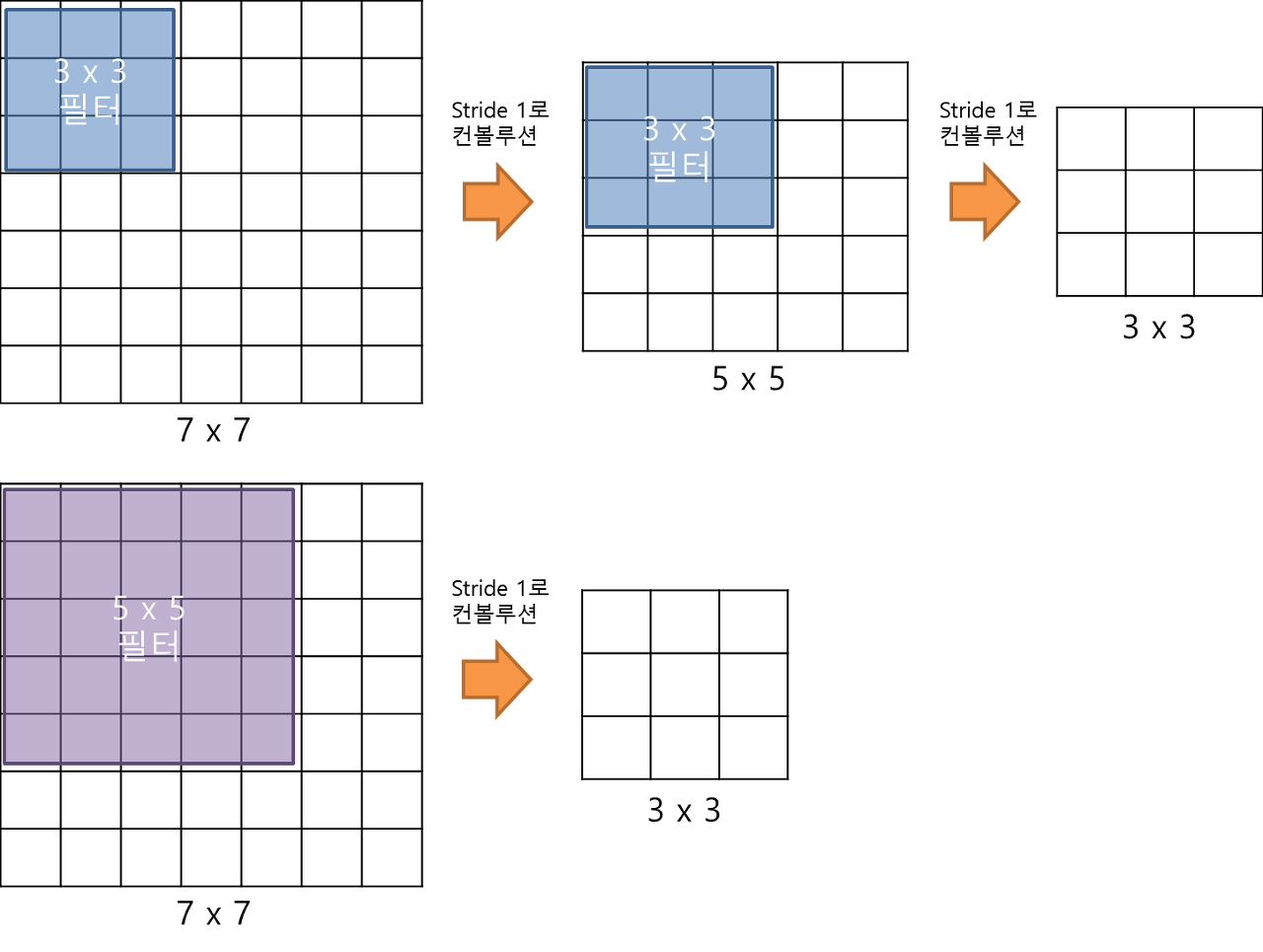
fig.4 convolution
3 x 3필터로 conv연산을 연달아서 하게 되면 5 x 5, 7 x 7등 큰 필터로 conv연산을 한 것과 동일한 크기의 feature map을 만들 수 있습니다. 이렇게 만들어진 featue map은 동일한 크기를 갖지만 파라메타 갯수에서 큰 차이를 보입니다. 파라메타가 적기 때문에 학습 속도가 빨라지고, 층이 많아서 비선형성을 증가 시켜 학습 되는 특징들이 점점 유용해 집니다.
3nd Gen GoogLeNet - 2014 ILSRVC winner
inception v1이라고도 부르는 네트워크 입니다. 크리스토퍼 놀란 감독의 영화 인셉션 처럼 네트워크 안에 네트워크를 가지고 있는 구조입니다. 후속 모델들이 inception v2, v3, v4를 달고 나오기 때문에 inception 모델에 익숙해지는게 좋을것 같습니다.
자세하게 설명하면 굉장히 길어지고 간단하게 알아보기가 취지인 글에 맞지 않기 때문에 핵심적인 요소만 서술 하고 넘어가고자 하니 자세한 내용은 CS231N, 라온 피플등을 참조 해주세요. 이 모델은 핵심적 요소만 나열 하겠습니다. 언젠가 단독 포스팅을 기다려 주세요…
- Network in Network 구조를 채택해 다른 크기의
conv레이어를 병렬로 사용합니다. 1 x 1 conv차원 축소를 통해 파라메타의 갯수를 줄입니다. 곧 올라올 포스팅을 기다려 주세요.
v2, v3에서는 batch normalization이 추가 되었습니다.
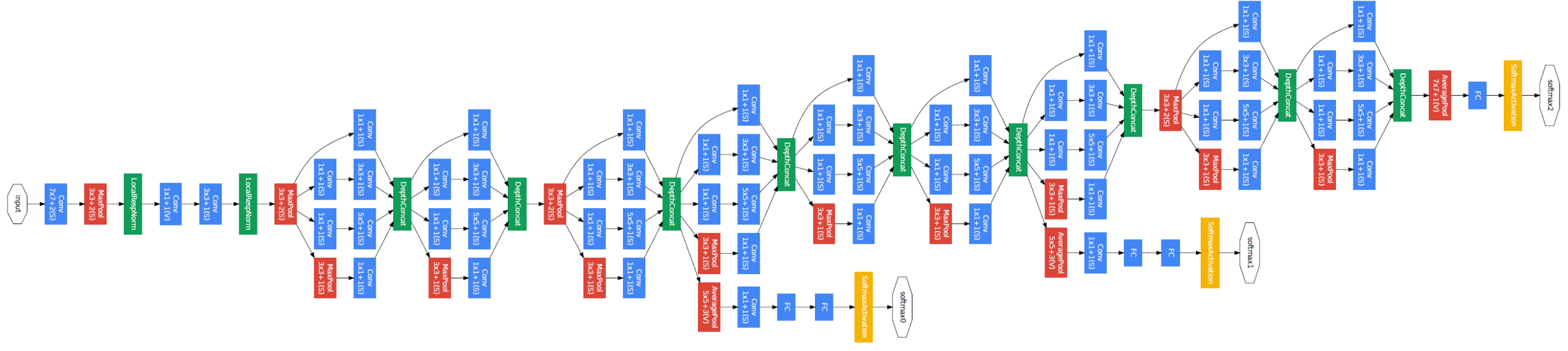
fig.5 GoogLeNet
4th Gen ResNet
ILSVRC 2015년도 우승 모델인 ResNet은 앞선 모델들에 비해 굉장히 깊어졌습니다. VGGNet이 19개층, GoogLeNet이 22개층인데 ResNet은 152개층을 가지고 있습니다. VGG연구팀도 19층보다 더 깊은 구조를 연구했었지만 오히려 에러가 증가하는 결과를 가져왔습니다. 이는 층이 깊어 질수록 서두에서 언급한 Vanishing/Exploding 문제와 기하급수적으로 많아지는 파라메타의 갯수 때문입니다. 이 때문에 GoogLeNet 또한 1 x 1 conv를 통해 파라메타를 줄였습니다. 파라메타가 너무 많아지면 overfitting 뿐만 아니라 에러도 커지는 문제를 가지고 있습니다.
ResNet에서는 이 문제 해결을 위해 Residual module을 사용합니다. residual module의 핵심 개념은 입력과 출력의 차이를 학습해서 backpropagation의 연산량을 줄인다는 것입니다. 이를 통해 깊은 망의 최적화가 쉬워졌고, 늘어난 깊이 덕에 정확도가 비약적으로 상승했습니다. 1 x 1 conv를 이용해 파라메타를 줄이고, VGG팀의 설계 철학을 이용해 대부분의 conv레이가 3 x 3크기를 가지게 들었습니다. 또한 연산량 감소를 위해 max-pooling, hidden fc, dropout등을 사용하지 않았습니다.
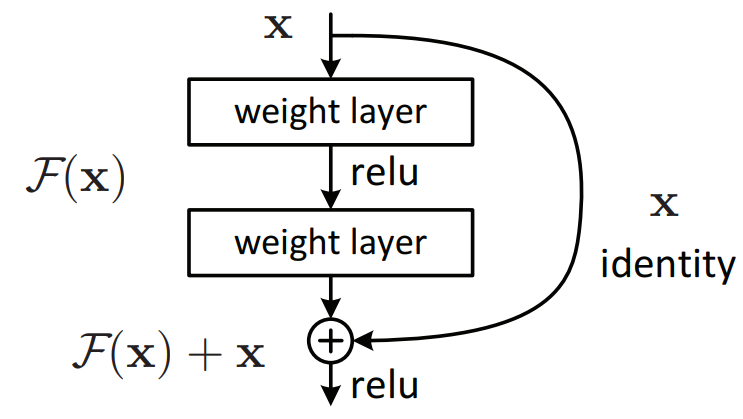
fig.6 residual module
본 글은 다음 글들을 참조하여 작성되었습니다.
[1] https://bskyvision.com/421
[2] https://laonple.blog.me/220654387455
[3] https://bskyvision.com/504?category=635506
[4] https://laonple.blog.me/220704822964
[5] https://laonple.blog.me/220761052425
논문 레퍼런스